
White Paper: Plumbing Before Prompts: Building RAG-Ready Data Architecture for Reliable GenAI

Executive Summary
The adoption of GenAI and Retrieval-Augmented Generation (RAG) represents a seismic shift in enterprise data strategy. Yet, while the market rushes to exploit GenAI for competitive advantage, the foundational challenge remains unchanged: enterprise data plumbing is broken. Without disciplined, secure, and connected data estates, businesses cannot scale AI initiatives or trust the outputs they generate. This white paper examines why structured and unstructured data management must precede any RAG ambitions and outlines a practical blueprint for building data infrastructure fit for enterprise-grade AI.
1. Introduction: The Illusion of Ready AI
RAG has popularised the notion that AI can be quickly bolted onto existing enterprise data. In theory, it offers a shortcut: connect your knowledge bases, enhance LLMs with real-time context, and generate reliable, business-ready outputs.
In practice, RAG reveals a harsh truth: your AI is only as good as your data plumbing.
Poorly governed, siloed, or outdated data undermines every AI promise. Hallucinations, compliance risks, and erosion of trust are not bugs; they are symptoms of systemic data failures. The proliferation of GenAI has only heightened the need for robust data architecture; pipelines, governance, security, and lineage must come first.
Moreover, the urgency of this requirement is only intensifying. Organisations eager to harness AI for competitive differentiation often underestimate the complexity of data integration. Fragmented data environments not only inhibit AI efficacy but also elevate risk across the business.
2. The Architecture of Discipline: What 'Good Plumbing' Looks Like
2.1 Unified, Hybrid Data Models
The future of enterprise AI depends on breaking down the barriers between structured and unstructured data. Hybrid data architectures (lakehouses) combine the scalability of data lakes with the governance and performance of warehouses. They form the foundation for unified, queryable, and AI-ready data estates.
Hybrid models enable RAG systems to draw from a single, cohesive data layer (structured ERP data, unstructured documents, semi-structured logs) all accessible within a controlled, secure framework.
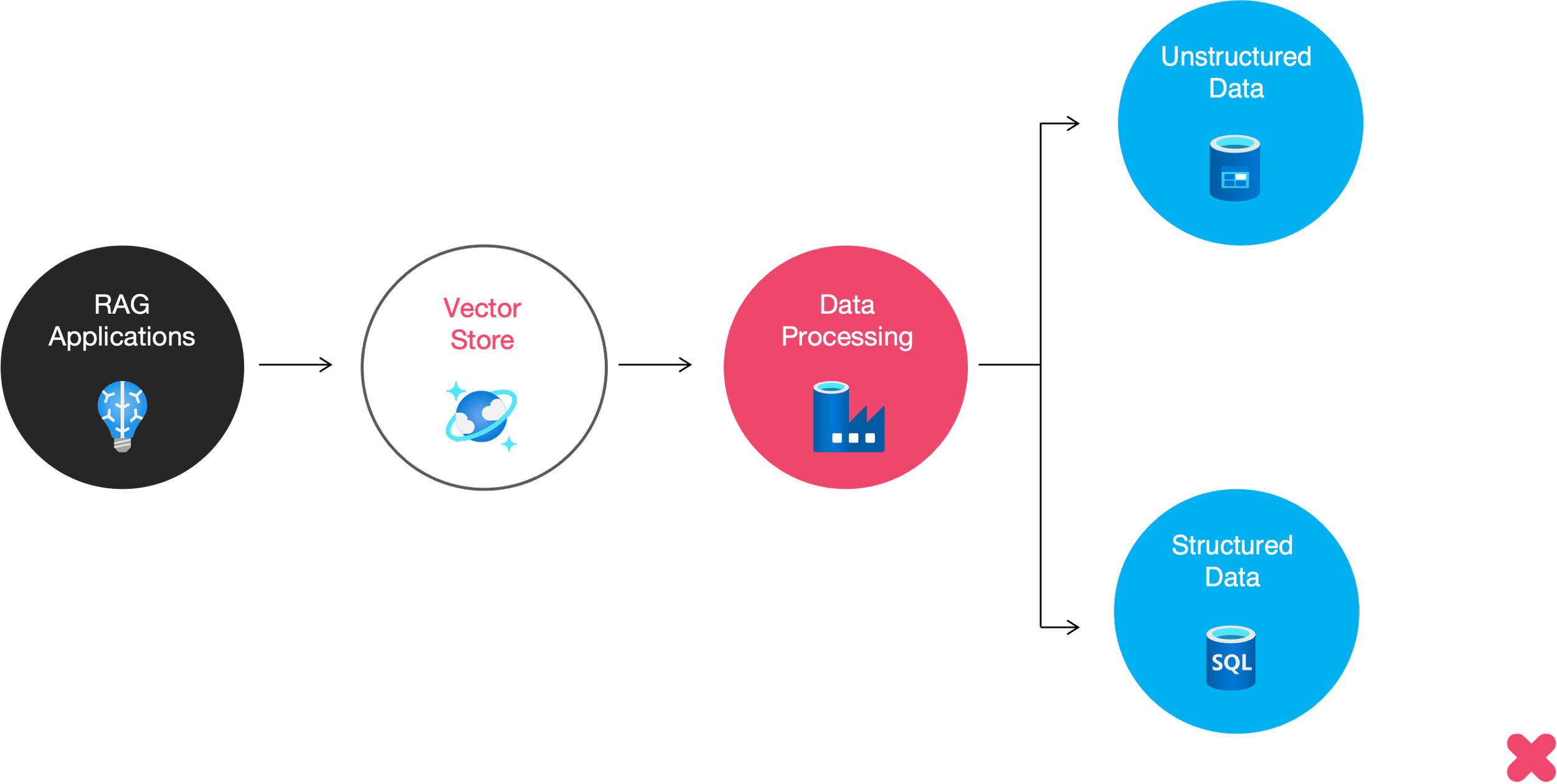
Unified Architecture
2.2 Automated, End-to-End Data Pipelines
Successful RAG architectures require pipelines that automate:
Ingestion across structured and unstructured sources
Preprocessing: parsing, cleansing, enrichment
Chunking for retrieval efficiency
Embedding for semantic search
Continuous updates for data freshness
Automated pipelines reduce manual intervention, enhance consistency, and accelerate time-to-value. They also support observability tools that allow data teams to trace errors, monitor flows, and ensure alignment with business KPIs.
2.3 Governance and Lineage as First-Class Citizens
Data governance is non-negotiable. Catalogue assets, define lineage, enforce access controls, and embed security from ingestion to output.
Catalogue & Metadata Management: Living inventory of assets, owners, and context
Lineage Tracking: Transparency from source to prompt-level interaction
Access Controls: RBAC and sensitivity-aware policies
Compliance Readiness: GDPR, HIPAA, CCPA baked into pipelines
"Why Data Lineage Is Essential for Effective AI Governance" https://www.zendata.dev/post/why-data-lineage-is-essential-for-effective-ai-governance
Without robust governance, enterprises face regulatory non-compliance, security vulnerabilities, and strategic misalignment.
2.4 Security by Design
Security underpins trust:
Encryption in transit and at rest
Tokenisation and masking of PII
API security for retrieval endpoints
Output-level filtering for leakage prevention
Embedding security throughout the data lifecycle mitigates risk, fortifies stakeholder confidence, and ensures readiness for evolving regulatory landscapes.
"Data Governance for RAG" https://enterprise-knowledge.com/data-governance-for-retrieval-augmented-generation-rag/
2.5 Prompt Design: The Overlooked Key to RAG Effectiveness
The quality of retrieval depends not only on the data architecture but also on how effectively prompts are structured to query it. Poorly designed prompts generate weak retrieval signals, even against well-prepared data. This two-sided relationship underscores why RAG-readiness requires both technical infrastructure and AI literacy at the user level.
3. Why This Matters: Risks of Undisciplined Data Architecture
3.1 Hallucination and Business Risk
AI that retrieves incomplete, stale, or inaccurate data delivers confidently wrong answers. These outputs degrade customer trust, damage brand equity, and expose companies to operational and financial risk.
Consider industries like healthcare, finance, and legal where precision is paramount. Errors amplified by AI can lead to catastrophic consequences, from misdiagnoses to compliance violations.
3.2 Compliance and Legal Exposure
Without lineage and governance, enterprises cannot defend against regulatory scrutiny or data breach litigation. Compliance frameworks demand provable data management.
Emerging AI regulations, including the EU AI Act and updates to GDPR, place a spotlight on explainability, auditability, and data provenance. Businesses must prepare now or face mounting liability.
3.3 Operational Inefficiency and Burnout
Ad-hoc AI initiatives waste time firefighting data issues. This stifles innovation, burns talent, and delays ROI.
Teams that repeatedly confront inconsistent data and unreliable outputs experience frustration and attrition. Building reliable infrastructure reduces churn and enhances innovation velocity.
"RAG Architecture Explained: A Comprehensive Guide (2025)" https://orq.ai/blog/rag-architecture
4. Blueprint for RAG-Ready Data Infrastructure
4.1 Baseline Your Data Estate
Inventory structured and unstructured sources
Identify silos, duplication, and stale data
Classify sensitivity and compliance requirements
A comprehensive data audit is the first step toward clarity and control. This includes mapping data lineage, assessing quality, and aligning sources with business objectives.
4.2 Establish Unified Data Models
Transition toward lakehouse architectures (Azure Synapse / MS Fabric)
Integrate with pipelines capable of hybrid workloads
Unified models reduce complexity, enable consistent governance, and enhance retrieval effectiveness.
4.3 Build Robust Pipelines
Automate ingestion, enrichment, embedding
Ensure observability and scalability
Align with security and governance from day one
Well-designed pipelines increase data agility, reduce time-to-insight, and improve AI output quality.
4.4 Embed Governance and Security
Implement catalogue tools (e.g., Purview)
Enforce lineage, RBAC, encryption, and monitoring
Robust governance frameworks create defensible processes and fortify organisational trust.
"Data Pipelines for RAG" https://www.amazee.io/blog/post/data-pipelines-for-rag/
4.5 Validate with Pilot Use Cases
Controlled deployments with human-in-the-loop validation
Monitor accuracy, latency, and compliance continuously
Validation de-risks larger deployments, provides insights for refinement, and builds confidence across stakeholders.
Diagram: End-to-end process from data ingestion to RAG application outputs with feedback loops.
5. The Future of AI Belongs to Disciplined Data Architects
AI adoption is no longer optional. But scalable, trustworthy AI demands robust, disciplined, and future-proof data architecture. Retrieval-Augmented Generation can only succeed when grounded in governance, security, and architectural clarity.
At GAPx, we help businesses transform theory into reality, building data estates designed to serve today's GenAI and tomorrow's innovations.
Organisations that prioritise data architecture today will dominate the AI-driven economy tomorrow.
"Leveraging Generative AI with RAG Architecture and Enterprise Data" https://www.programmersinc.com/leveraging-generative-ai-with-rag-architecture-and-enterprise-data/
Further Reading / References
https://www.k2view.com/what-is-retrieval-augmented-generation
https://www.clouddatainsights.com/unlocking-autonomous-data-pipelines-with-generative-ai/
https://developer.nvidia.com/blog/rag-101-demystifying-retrieval-augmented-generation-pipelines/
https://www.aws.amazon.com/what-is/retrieval-augmented-generation/
Call to Action: Is Your Data Ready for AI?
Before you build prompts, fix the pipes. GAPx offers tailored assessments to baseline your data estate, design future-ready architectures, and operationalise AI with confidence.
Our proven frameworks help organisations future-proof their data strategies and unlock the full potential of GenAI.