
Plumbing Before Prompts: Why Clean, Connected Data Infrastructure is Essential for Trustworthy GenAI

Introduction: The False Comfort of RAG Without Foundations
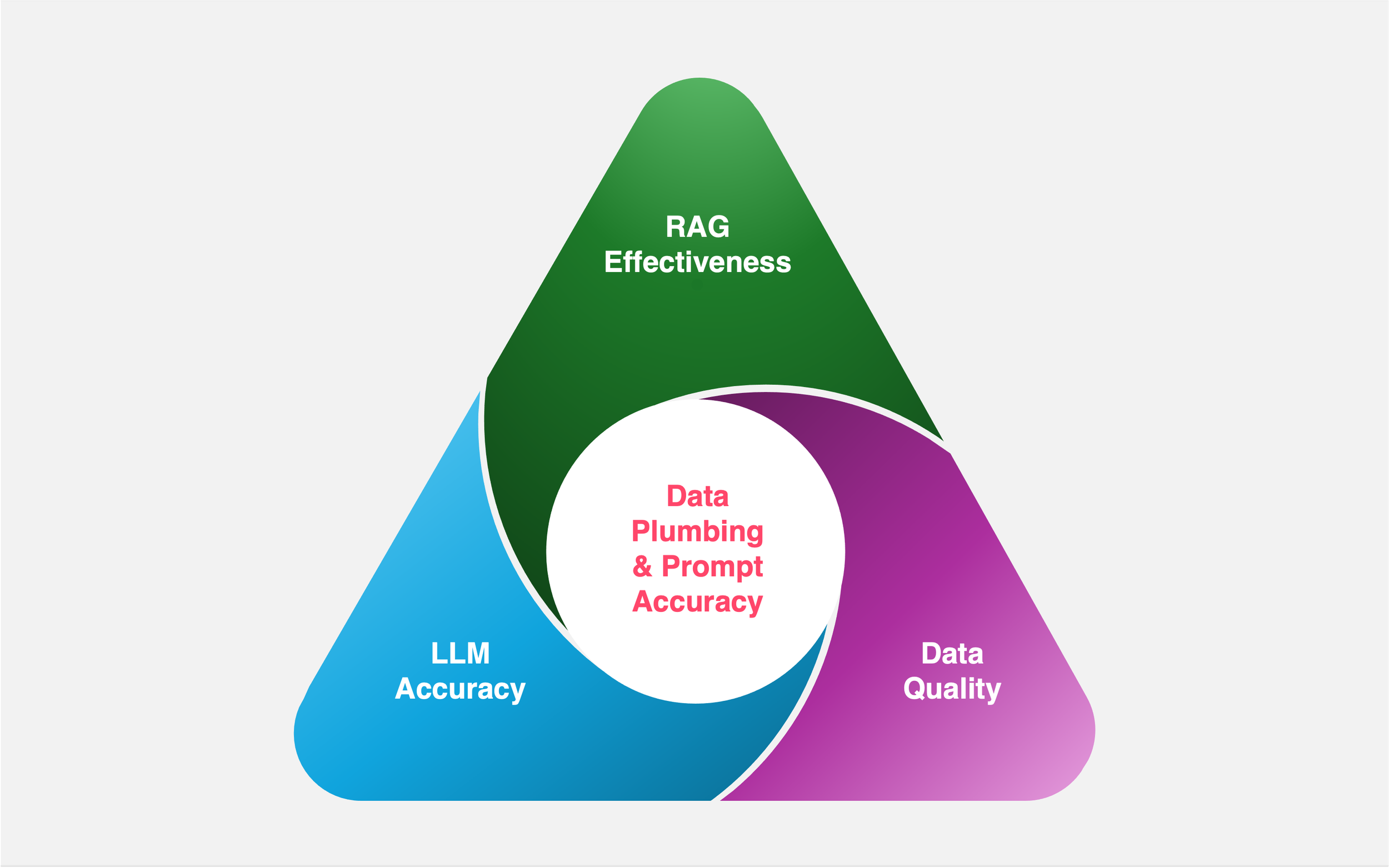
Retrieval-Augmented Generation (RAG) promises to unlock enterprise knowledge by augmenting Large Language Models (LLMs) with your company’s own data. But beneath the surface, many organisations are hurtling towards RAG implementations while ignoring the state of their data infrastructure. Dirty, siloed, inconsistent data cannot deliver reliable answers, no matter how sophisticated the model. GenAI doesn’t solve bad plumbing. It exposes it.
RAG succeeds or fails based on the quality, accessibility, and governance of structured and unstructured data. For PE-backed firms and mid-sized enterprises with ambitions to scale through AI, this means getting the data house in order – securely, systematically, and with future flexibility in mind.
Why Prompt Quality Matters as Much as Data Plumbing
Even with the best data estate, the prompt still matters. A vague or poorly structured question leads to vague or irrelevant retrieval. That’s why reliable outputs depend on both clean data and smart prompting strategies.
The Plumbing Problem: Why Most Data Estates Aren’t Ready
Despite the hype, most organisations still operate on fragmented, poorly governed data estates. Legacy systems, ad-hoc cloud migrations, Excel graveyards, and siloed CRMs create brittle foundations. Unstructured data lives unmanaged in SharePoint or email archives; structured data is spread across ERP modules with inconsistent taxonomies.
The result? LLMs retrieve incomplete or inaccurate information. Knowledge workers lose trust in outputs. Compliance teams raise red flags. Meanwhile, competitors with disciplined data strategies accelerate.
Research highlights this challenge:
“80-90% of enterprise data remains dark, unstructured and underutilised.” (TechRadar, 2025)
https://www.techradar.com/pro/transforming-dark-data-into-ai-driven-business-value
What Good Plumbing Looks Like
To be RAG-ready, enterprises must adopt a data architecture that integrates both structured and unstructured sources through disciplined pipelines and governance. In the Microsoft ecosystem, this often centres around Azure Data Lake, Synapse Analytics, and Data Factory, but the principles apply universally.
Key components:
Data Lakes for unstructured capture at scale (e.g., Azure Data Lake).
Data Warehouses / Fabric for structured integration (e.g., Azure Synapse / MS Fabric).
Pipelines / Factories for orchestrated, monitored ingestion (e.g., Azure Data Factory).
Vector Stores & Knowledge Graphs for semantic retrieval (futureproofing RAG).
Governance Frameworks: Metadata, lineage, RBAC, encryption, retention policies.
Why This Matters for GenAI: From Trust to Auditability
LLMs hallucinate when disconnected from trustworthy data. RAG mitigates this risk but only if retrieval is accurate, context-rich, and governed. Clean pipelines and connected systems reduce the chance of outdated, irrelevant, or inaccurate prompts feeding your GenAI applications.
This isn’t just about better answers; it’s about:
Trust: Can stakeholders rely on AI outputs in board meetings, audits, or customer conversations?
Auditability: Can you trace outputs back to specific data sources?
Compliance: Are PII and sensitive data protected within AI interactions?
Squirro notes:
“RAG is evolving into a critical layer for safe, enterprise-scale GenAI” (Squirro, 2025)
https://squirro.com/squirro-blog/state-of-rag-genai
GAPx’s Perspective: Prepare for Platform Agnosticism, Not Lock-In
GAPx works with Microsoft platforms but remains vendor-agnostic at a strategic level. The principle is simple: design data estates that serve any future model, not just today's GPT variant. That means open standards, robust APIs, and clear data ownership.
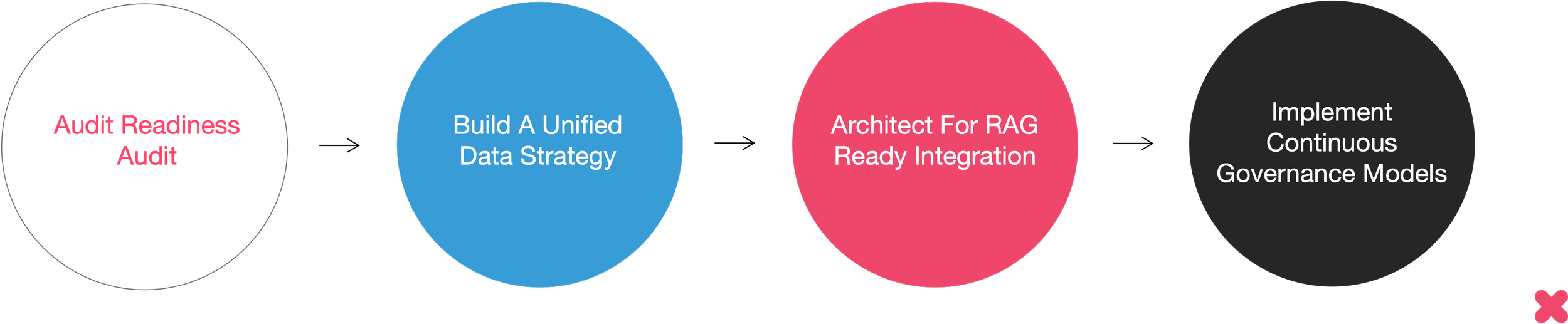
What we recommend:
Conduct a Data Readiness Audit
Build a Unified Data Strategy aligned to business outcomes
Architect for RAG-Ready Integration
Implement Continuous Governance Models
Conclusion: Before You Prompt, Fix the Pipes
GenAI is not magic. It’s an amplifier of what you already have – good or bad. To extract value from LLMs, organisations must first build data foundations capable of delivering clean, connected, compliant information on demand.
GAPx helps businesses make this transformation practical, not theoretical. From data lakes to governance, we ensure your next AI move is grounded in reality, not risk.
Further Reading:
Is Your Data Ready for AI?
Let’s start with a conversation.
For a deeper dive into how disciplined data architecture enables trustworthy, scalable GenAI, explore our full white paper: “Plumbing Before Prompts.”